Re: [閒聊] AI畫圖是不是大數據拼圖?
最近回去念書了,念的programme名字有AI,應該可以發個言ㄅ
新科技需要熱衷的族群做推廣,有推廣才有funding,我才有薪水qq
不過這些族群不一定對科技有正確的認識
這幾天看到一些不精確又容易誤導的解釋真的會中風
想說做點簡單的科普(科普很難我知道qq)
※ 引述《newwu (說不定我一生涓滴廢文)》之銘言:
: 見圖二
: 理解這個想法後
: 我們把圖像的高維空間畫成二維方便表示
: 以ACG圖為例
: 那被人類接受的ACG圖就是一個高維空間中的分佈
: 簡單理解就是一個範圍內的圖,會被視為可接受的ACG圖
: 在那個範圍外的空間包含相片 雜訊 古典藝術 支離破碎的圖
: 生成模型的目的,就是從範圍內的樣本(下圖紅點)建立一個模型
: 這個模型學習到這個範圍,而模型可以生成也只會生成在範圍內的點
: https://i.imgur.com/NfUyIAg.jpg

: 圖二
借用newwu的圖
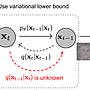
目前大家在討論的AI,其實更精確地講,應該說是圖像的生成模型Generative Models(GM)
GM有很多種
舉凡VAE, Autoregressive Models, GAN, Normalizing Flow, Denoising Diffusion都是
而一個被科學家普遍採用的假設是
真實世界資料的複雜分布(圖二),都對應到一個潛在空間latent space
而這個空間通常較具有可讀性(interpretable),例如某個維度代表某種面向
另外方便起見,現實資料這個潛在空間的分布會是個很簡單可操作的分布
大部分論文都用常態分布Gaussian,但我相信也有人用binomial分布之類
為甚麼要這麼設計? 因為如果假設為真,可以幫助我們去分析與理解現實的資料
科學研究本來就是要幫助人類進步,怎麼會搶繪師的飯碗
而大部分模型在做的事,就是學這個兩個空間的對應關係
訓練方式也很簡單,最大化資料在這兩個空間的可能性(likelihood)
VAE的潛在分布在一個低維空間
GAN雖然理論基礎薄弱導致先天性缺陷一大堆,但也是在modeling低維的空間
Normalizing Flow和Diffusion比較特別,潛在空間的維度和原始資料一樣
Autoregressive Models直接模擬現實的分布,但不影響上述的假設
至於Diffusion Models的貢獻還有表現為甚麼這麼好,以至於瘋狂的流行起來
比之前的GAN熱潮有過而無不及,主要是因為訓練Diffusion Model和訓練VAE一樣
都是在最大化分佈的下限 maximium lower bound
然而卻沒有VAE的模糊問題,證明只要分佈設計的好
是可以同時保持VAE的好訓練特色和GAN一樣的高likelihood
也不是沒有缺點
如果把整個生成過程攤開來看,Diffusion model就是一個超~~極深的神經網路
比ResNet還深,導致生成非常耗時,加速生成過程也是一個熱門的研究方向
如果對diffusion models有興趣,想快速了解也不排斥讀論文
我推薦這篇近期的overview paper,對整個diffusion models的不同面向都有做講解
https://ar5iv.labs.arxiv.org/html/2208.11970
也可以看板上cybermeow的解說
另外這篇的結語也非常有趣
就是人在畫圖的時候,是否也是藉由不斷的去噪,提煉出一張圖的?
diffusion實際上真的模擬的人類的創作過程嗎? 值得玩味
最後回答幾個常見的QA
Q: AI畫圖都是從別人的圖找出來拼貼的。
A: 沒有這種事。
從以上以及前幾篇的講解,可以知道生成模型從頭到尾在做的
就只是機率統計而已。
給予離散的資料點,找出最能代表的連續函數,僅此而已。
因為有loss的關係,要生出完全一模一樣的圖幾乎不可能
(當然也有生出不完全相同,但人類感知上無法察覺不同的情況
Q: AI繪圖只能迎合大眾的喜好,無法有獨創性,提出新的概念。
A: 這是個無法說死的問題。
理想上,數個資料如有類似的屬性,不管是畫風、概念、構圖
在潛在空間應該會落在一個鄰近的區域(cluster)
如果我們有足夠的資料、足夠強的模型架構,能真的完全模擬現實資料的潛在分佈
那麼所謂的沒出現在訓練資料,具有獨特性的繪圖
也許只是某個能內差或外插出來的區域而已。
當然也有可能AI繪圖影響到人類繪圖的整體分佈,脫離原本的潛在空間。
Q: diffusion的訓練過程和GAN相比,會直接看到訓練過程所以較強(#1ZFbZ85b)
A: Nonsense.
diffusion強大的原因在前文已經解釋了。
GAN不可能沒用到原圖的資訊,你如果把discriminator和generator並在一起當作同一個
模型就知道了。
VAE的訓練也會直接看到原圖,效果卻一般。
Q: CNN的filter是找最常出現的pattern,所以有用到其他圖的資訊去拼貼!
A: Also nonsense。
如果今天CNN只有一層,那還有一點道理。
但一到兩層以上,這些Hidden feature所在的空間和原本資料所在的空間已經是不同的了
要說拿圖去拼貼非常牽強。
大概醬,有問題可以直接推文,還得寫今天跟老闆的會議紀錄QQ
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 31.205.105.234 (英國)
※ 文章網址: https://www.ptt.cc/bbs/C_Chat/M.1665072277.A.6FA.html
推
10/07 00:06,
1年前
, 1F
10/07 00:06, 1F
→
10/07 00:07,
1年前
, 2F
10/07 00:07, 2F
→
10/07 00:08,
1年前
, 3F
10/07 00:08, 3F
→
10/07 00:08,
1年前
, 4F
10/07 00:08, 4F
推
10/07 00:09,
1年前
, 5F
10/07 00:09, 5F
→
10/07 00:10,
1年前
, 6F
10/07 00:10, 6F
→
10/07 00:10,
1年前
, 7F
10/07 00:10, 7F
→
10/07 00:10,
1年前
, 8F
10/07 00:10, 8F
→
10/07 00:12,
1年前
, 9F
10/07 00:12, 9F
推
10/07 00:12,
1年前
, 10F
10/07 00:12, 10F
→
10/07 00:13,
1年前
, 11F
10/07 00:13, 11F
推
10/07 00:13,
1年前
, 12F
10/07 00:13, 12F
→
10/07 00:15,
1年前
, 13F
10/07 00:15, 13F
→
10/07 00:16,
1年前
, 14F
10/07 00:16, 14F
→
10/07 00:16,
1年前
, 15F
10/07 00:16, 15F
推
10/07 00:18,
1年前
, 16F
10/07 00:18, 16F
→
10/07 00:18,
1年前
, 17F
10/07 00:18, 17F
→
10/07 00:18,
1年前
, 18F
10/07 00:18, 18F
推
10/07 00:19,
1年前
, 19F
10/07 00:19, 19F
→
10/07 00:20,
1年前
, 20F
10/07 00:20, 20F
推
10/07 00:21,
1年前
, 21F
10/07 00:21, 21F
→
10/07 00:22,
1年前
, 22F
10/07 00:22, 22F
推
10/07 00:22,
1年前
, 23F
10/07 00:22, 23F
→
10/07 00:24,
1年前
, 24F
10/07 00:24, 24F
→
10/07 00:24,
1年前
, 25F
10/07 00:24, 25F
→
10/07 00:25,
1年前
, 26F
10/07 00:25, 26F
→
10/07 00:25,
1年前
, 27F
10/07 00:25, 27F
→
10/07 00:25,
1年前
, 28F
10/07 00:25, 28F
→
10/07 00:25,
1年前
, 29F
10/07 00:25, 29F
→
10/07 00:26,
1年前
, 30F
10/07 00:26, 30F
→
10/07 00:28,
1年前
, 31F
10/07 00:28, 31F
→
10/07 00:28,
1年前
, 32F
10/07 00:28, 32F
→
10/07 00:28,
1年前
, 33F
10/07 00:28, 33F
→
10/07 00:28,
1年前
, 34F
10/07 00:28, 34F
→
10/07 00:29,
1年前
, 35F
10/07 00:29, 35F
推
10/07 00:29,
1年前
, 36F
10/07 00:29, 36F
→
10/07 00:29,
1年前
, 37F
10/07 00:29, 37F
→
10/07 00:29,
1年前
, 38F
10/07 00:29, 38F
→
10/07 00:29,
1年前
, 39F
10/07 00:29, 39F
還有 24 則推文
還有 4 段內文
→
10/07 01:24,
1年前
, 64F
10/07 01:24, 64F
→
10/07 01:24,
1年前
, 65F
10/07 01:24, 65F
→
10/07 01:24,
1年前
, 66F
10/07 01:24, 66F
→
10/07 01:24,
1年前
, 67F
10/07 01:24, 67F
推
10/07 01:27,
1年前
, 68F
10/07 01:27, 68F
→
10/07 01:27,
1年前
, 69F
10/07 01:27, 69F
→
10/07 01:27,
1年前
, 70F
10/07 01:27, 70F
→
10/07 01:29,
1年前
, 71F
10/07 01:29, 71F
→
10/07 01:29,
1年前
, 72F
10/07 01:29, 72F
推
10/07 01:36,
1年前
, 73F
10/07 01:36, 73F
→
10/07 01:37,
1年前
, 74F
10/07 01:37, 74F
推
10/07 01:45,
1年前
, 75F
10/07 01:45, 75F
推
10/07 01:50,
1年前
, 76F
10/07 01:50, 76F
推
10/07 01:51,
1年前
, 77F
10/07 01:51, 77F
推
10/07 02:08,
1年前
, 78F
10/07 02:08, 78F
→
10/07 02:08,
1年前
, 79F
10/07 02:08, 79F
推
10/07 02:15,
1年前
, 80F
10/07 02:15, 80F
噓
10/07 02:17,
1年前
, 81F
10/07 02:17, 81F
→
10/07 02:17,
1年前
, 82F
10/07 02:17, 82F
→
10/07 02:17,
1年前
, 83F
10/07 02:17, 83F
推
10/07 02:23,
1年前
, 84F
10/07 02:23, 84F
→
10/07 02:23,
1年前
, 85F
10/07 02:23, 85F
→
10/07 02:24,
1年前
, 86F
10/07 02:24, 86F
→
10/07 02:24,
1年前
, 87F
10/07 02:24, 87F
推
10/07 02:32,
1年前
, 88F
10/07 02:32, 88F
→
10/07 04:23,
1年前
, 89F
10/07 04:23, 89F
→
10/07 04:23,
1年前
, 90F
10/07 04:23, 90F
→
10/07 04:26,
1年前
, 91F
10/07 04:26, 91F
→
10/07 04:26,
1年前
, 92F
10/07 04:26, 92F
→
10/07 04:31,
1年前
, 93F
10/07 04:31, 93F
→
10/07 04:31,
1年前
, 94F
10/07 04:31, 94F
推
10/07 07:22,
1年前
, 95F
10/07 07:22, 95F
→
10/07 07:22,
1年前
, 96F
10/07 07:22, 96F
推
10/07 07:59,
1年前
, 97F
10/07 07:59, 97F
→
10/07 08:01,
1年前
, 98F
10/07 08:01, 98F
推
10/07 08:47,
1年前
, 99F
10/07 08:47, 99F
推
10/07 08:52,
1年前
, 100F
10/07 08:52, 100F
推
10/07 09:39,
1年前
, 101F
10/07 09:39, 101F
推
10/07 15:50,
1年前
, 102F
10/07 15:50, 102F
推
10/07 20:12,
1年前
, 103F
10/07 20:12, 103F
討論串 (同標題文章)