Re: [閒聊] AI畫圖是不是大數據拼圖?
※ 引述《KyrieIrving1 (King of New York)》之銘言:
: 大家最近討論的AI畫圖
: 我本來以為真的是AI汲取各種關鍵字
: 然後用算的方式算出圖陣
: 看大家玩下來
: 比較像是AI去全球所有的圖畫數據庫裡面
: 用各種關鍵字的圖去拼出一張新的圖?
: 如果是算圖 那真的是新創
: 可是如果是拼圖 很容易發現到底從哪拼出來的吧
: 還是我理解有誤
: AI畫圖是大數據拼圖嗎??
首先當然是算的
如果要從全球資料庫找圖再拼圖 那硬碟空間跟運算時間都會非常驚人
從實際面來看很難做到像現在5秒就出一張圖
再來是目前很紅的Novel AI
目前畫風統一程度確實不像一般Stable Difussion
比較有可能的是他有另外訓練一個畫風轉換的模型
分兩步驟 先是用SD生圖 再丟到另外的模型做畫風轉換
當然這另外的畫風模型 是另外請人畫還是直接拿現成圖就不知道了
而以技術層面來講
Stable Difussion新提出的方法 跟以前比起來確實比較有爭議
以前GAN的做法 並不會直接用原圖訓練生圖AI(Generator)
而是另外訓練一個判斷AI(Discriminator) 負責判斷哪些是"好"的圖
生圖AI會隨機生圖 根據是否能通過判斷AI的標準 來調整自己
因此生圖AI出來的圖 是完全沒看過或參考其他圖的
雖然在判斷AI那邊還是拿了別人的圖 但至少生圖AI從來沒參考過其他圖
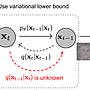
而新提出的Stable Difussion 則是在生圖AI加了一個降噪(Denoising)的訓練過程
生圖AI的目的變成將噪點(latent noise)還原成一般圖
而用來訓練生圖AI的資料 就是直接拿原圖不斷增加噪點 讓AI學習如何去噪點
在訓練的過程中就不免會學習到原圖的特徵
最後出來的效果很好 但就會有一些爭議
最近效果也很好的DALL-E 2也用到了Difussion的概念
除非未來又能發展出不需要參考原圖的技術 不然未來很難避免這類爭議
學習現實物體的特徵沒什麼爭議 畢竟物體就是物體 其特徵只是客觀存在
但學習畫作時 直接學習圖畫的特徵
其中的骨架 筆觸 光影 都是畫家自身的技術 不是單純的物體特徵
而現今法律並沒有保護這塊
畫風跟風格的模仿與致敬在ACG上也不少見 但也沒聽說過幾個真的引起法律問題的
不過AI出現讓門檻降低 未來要模仿他人畫風變得相當容易
這部分自然就會引起不少爭議
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 98.47.62.151 (美國)
※ 文章網址: https://www.ptt.cc/bbs/C_Chat/M.1665030344.A.165.html
推
10/06 12:28,
1年前
, 1F
10/06 12:28, 1F
→
10/06 12:28,
1年前
, 2F
10/06 12:28, 2F
推
10/06 12:29,
1年前
, 3F
10/06 12:29, 3F
推
10/06 12:33,
1年前
, 4F
10/06 12:33, 4F
推
10/06 12:33,
1年前
, 5F
10/06 12:33, 5F
→
10/06 12:34,
1年前
, 6F
10/06 12:34, 6F
→
10/06 12:35,
1年前
, 7F
10/06 12:35, 7F
推
10/06 12:35,
1年前
, 8F
10/06 12:35, 8F
→
10/06 12:35,
1年前
, 9F
10/06 12:35, 9F
→
10/06 12:35,
1年前
, 10F
10/06 12:35, 10F
→
10/06 12:36,
1年前
, 11F
10/06 12:36, 11F
→
10/06 12:37,
1年前
, 12F
10/06 12:37, 12F
→
10/06 12:37,
1年前
, 13F
10/06 12:37, 13F
推
10/06 12:40,
1年前
, 14F
10/06 12:40, 14F
推
10/06 12:41,
1年前
, 15F
10/06 12:41, 15F
→
10/06 12:45,
1年前
, 16F
10/06 12:45, 16F
推
10/06 12:49,
1年前
, 17F
10/06 12:49, 17F
推
10/06 13:23,
1年前
, 18F
10/06 13:23, 18F
→
10/06 13:23,
1年前
, 19F
10/06 13:23, 19F
→
10/06 13:23,
1年前
, 20F
10/06 13:23, 20F
噓
10/06 15:30,
1年前
, 21F
10/06 15:30, 21F
→
10/06 15:30,
1年前
, 22F
10/06 15:30, 22F
→
10/06 15:39,
1年前
, 23F
10/06 15:39, 23F
→
10/06 15:39,
1年前
, 24F
10/06 15:39, 24F
→
10/06 15:49,
1年前
, 25F
10/06 15:49, 25F
→
10/06 15:49,
1年前
, 26F
10/06 15:49, 26F
→
10/06 15:51,
1年前
, 27F
10/06 15:51, 27F
→
10/06 15:51,
1年前
, 28F
10/06 15:51, 28F
→
10/06 16:33,
1年前
, 29F
10/06 16:33, 29F
→
10/06 16:34,
1年前
, 30F
10/06 16:34, 30F
→
10/06 16:34,
1年前
, 31F
10/06 16:34, 31F
→
10/06 16:36,
1年前
, 32F
10/06 16:36, 32F
→
10/06 16:37,
1年前
, 33F
10/06 16:37, 33F
→
10/06 16:37,
1年前
, 34F
10/06 16:37, 34F
→
10/06 16:41,
1年前
, 35F
10/06 16:41, 35F
→
10/06 16:41,
1年前
, 36F
10/06 16:41, 36F
→
10/06 18:42,
1年前
, 37F
10/06 18:42, 37F
→
10/06 18:42,
1年前
, 38F
10/06 18:42, 38F
→
10/06 20:09,
1年前
, 39F
10/06 20:09, 39F
→
10/06 20:10,
1年前
, 40F
10/06 20:10, 40F
討論串 (同標題文章)