Re: [閒聊] AI畫圖是不是大數據拼圖?
我很久以前連waifu diffusion都還沒出來就發過了
https://www.pttweb.cc/bbs/C_Chat/M.1661681711.A.DE3
複製貼上自己的文章算抄襲嗎
--------------------
造成這波圖像生成革命的推手
正式所謂的 Diffusion / Score-matching model 系列
一般往前最早大約推到2015年這篇文章 [1]
https://arxiv.org/abs/1503.03585
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
不過船過水無痕 之後幾年還是一直由GAN (Generative Adversarial Netwok 生成對抗網路
) 統領生成模型這塊
直到2019年後兩派人馬分別用不同個觀點把這系列的效果真的做起來後
才有我們今天所看到的這些結果
所以說 Diffusion model 到底是什麼 會什麼效果可以這麼好
下面分三個面向來談
真的想深入了解的很推薦今年 CVPR 的 tutorial
https://cvpr2022-tutorial-diffusion-models.github.io/
深入淺出的從不同面向介紹這些模型
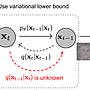
1. Diffusion model as denoiser
最直覺最好解釋 同時也可能是最正確的觀點
是把 Diffusion model 當作一個不斷去噪的過程
以下圖片分別取自 DDPM 的 Paper [2] 以及上面提到的 tutorial
https://imgur.com/kkj76zH


第一張圖示從右到左 x0 到 xT 不斷地加噪音
而訓練是學習如何把不同程度噪音的圖片還原成原本的資料
由於還原無法完美 所以嘗試還原再加上一定程度的噪音
相當於學習如何從一個噪音較多的 xt 到一個噪音較少的 x_{t-1}
而最後生成圖片的時候
則是從白噪音不斷去噪 得到我們所見到的成果
至於為什麼這簡單的解釋正是真的的原因 可以參考
Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise [3]
2. Diffusion model as maximum-likelihood model
數學的角度上來講
Diffusion model 跟任何機率模型一樣
(Gaussian mixture, Hidden markov chain or whatever
都是由許多參數來描述一個機率
也就是經過上面一部一部去噪所得到的機率分佈
不過它由於利用許多如今神經網路的特性所以效果特別好
稍微讀過統計的人大概都聽過
學習一個模型最常用的就是 maximum-likelihood
白話來說 就是如何找到一組參數使得在這個參數下觀察到手邊資料的機率是最大的
而所謂訓練去除噪音的過程
其實就是在最小化訓練集機率分佈跟模型機率分佈的交叉熵的某個上界
以達到 maximum likelihood 的效果
詳細推導可以參考
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
而這也是 DDPM [2] 或者 2015 那篇 [1] 的看法
另外同樣機率模型來說 Diffusion model 也可以看作一種 energy model
又或者是 hierarchical VAE 的特例
3. Diffusion model as discretization of a reverse stochastic differential equati
on
如果把剛剛一部一部往前加噪音連續化
那將成為一個隨機微分方程的軌跡 (trajectory)
將它從我們感興趣的圖片的機率分佈帶到高斯噪音
而這個隨機微分方程其實是可逆的
往回走得過程需要學每一個時間點的 score function
也就是 gradient of log density
如同下圖所示 (取自 https://yang-song.net/blog/2021/score/ 那邊有詳細解釋
https://imgur.com/fprfULR

而其實學習如何去噪 也可以理解成在學習這個 score function
上面的 sampling process 也跟學好 score function 後沿著這個 reverse SDE 走回來有
異曲同工之妙
另外同樣 score function 系列的
比較早期的 Annealed Langevin Dynamics 也是類似的概念
--------------------
好貼完了
今天出了waifu diffusion 1.3
https://huggingface.co/hakurei/waifu-diffusion-v1-3
跟hentai diffusion 1214
https://huggingface.co/Deltaadams/Hentai-Diffusion/tree/main
正在測效果但不會下prompt
崩潰
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 172.58.43.212 (美國)
※ 文章網址: https://www.ptt.cc/bbs/C_Chat/M.1665033024.A.A40.html
→
10/06 13:11,
1年前
, 1F
10/06 13:11, 1F
推
10/06 13:11,
1年前
, 2F
10/06 13:11, 2F
→
10/06 13:11,
1年前
, 3F
10/06 13:11, 3F
※ 編輯: cybermeow (172.58.43.212 美國), 10/06/2022 13:13:11
推
10/06 13:13,
1年前
, 4F
10/06 13:13, 4F
推
10/06 13:14,
1年前
, 5F
10/06 13:14, 5F
→
10/06 13:15,
1年前
, 6F
10/06 13:15, 6F
推
10/06 13:17,
1年前
, 7F
10/06 13:17, 7F
推
10/06 13:17,
1年前
, 8F
10/06 13:17, 8F
→
10/06 13:17,
1年前
, 9F
10/06 13:17, 9F
推
10/06 13:17,
1年前
, 10F
10/06 13:17, 10F
推
10/06 13:17,
1年前
, 11F
10/06 13:17, 11F
→
10/06 13:17,
1年前
, 12F
10/06 13:17, 12F
→
10/06 13:17,
1年前
, 13F
10/06 13:17, 13F
不太確定你的意思
我做gradient descente也可以全部當作是在dual space
反正詮釋方法很多種 我跟sde也不熟
→
10/06 13:18,
1年前
, 14F
10/06 13:18, 14F
都是 有些回推過程每一步都有噪音
像是Euler a
那就是起始噪音跟每一步的噪音
推
10/06 13:19,
1年前
, 15F
10/06 13:19, 15F
推
10/06 13:20,
1年前
, 16F
10/06 13:20, 16F
啊對了還要解釋clip embedding跟text to image
板上神人那麼多等別人發好了 我要繼續玩新出的模型www
反正大概念就是把那個文字訊息訓練去噪時也當輸入讓他一起學
所以才需要用有文字描述的訓練集
至於怎麼讓輸入文字變成模型懂的又是一門學問
推
10/06 13:21,
1年前
, 17F
10/06 13:21, 17F
※ 編輯: cybermeow (172.58.43.212 美國), 10/06/2022 13:23:03
推
10/06 13:24,
1年前
, 18F
10/06 13:24, 18F
推
10/06 13:26,
1年前
, 19F
10/06 13:26, 19F
→
10/06 13:26,
1年前
, 20F
10/06 13:26, 20F
推
10/06 13:26,
1年前
, 21F
10/06 13:26, 21F
※ 編輯: cybermeow (172.58.43.212 美國), 10/06/2022 13:27:04
推
10/06 13:28,
1年前
, 22F
10/06 13:28, 22F
→
10/06 13:28,
1年前
, 23F
10/06 13:28, 23F
推
10/06 13:31,
1年前
, 24F
10/06 13:31, 24F
→
10/06 13:31,
1年前
, 25F
10/06 13:31, 25F
→
10/06 13:31,
1年前
, 26F
10/06 13:31, 26F
推
10/06 13:33,
1年前
, 27F
10/06 13:33, 27F
推
10/06 13:33,
1年前
, 28F
10/06 13:33, 28F
推
10/06 14:17,
1年前
, 29F
10/06 14:17, 29F
推
10/06 14:18,
1年前
, 30F
10/06 14:18, 30F
推
10/06 14:51,
1年前
, 31F
10/06 14:51, 31F
→
10/06 15:19,
1年前
, 32F
10/06 15:19, 32F
推
10/06 16:21,
1年前
, 33F
10/06 16:21, 33F
推
10/06 16:49,
1年前
, 34F
10/06 16:49, 34F
討論串 (同標題文章)