Re: [閒聊] えなこ跟國昌真的相似嗎?人臉辨識告
※ 引述《can18 (18號)》之銘言:
: 我覺得原 Po 犯了幾點錯誤
: 1. 人臉識別的技術
: 人臉識別最主要的目的是將相同的人視為相同的人 不同的人視為不同的人
: 數值代表的是為同一個人的機率 並不是兩個人的相似程度
: 人臉識別不會保證相似的人的分數一定會比不相似的人高
: (當然實務上相似的人分數很可能比不相似的高 但不是必然
: 事實上 有一篇論文叫做
: Measuring Face Similarity Rather than Face Identity
: (CVPR 2018 頂級的電腦視覺會議論文)
: 如果可以直接用人臉識別的分數推論相似 這篇論文根本不會存在
: 2. 相似的定義
: 假設你真的得到機器的相似分數
: 大家說的像 相似
: 通常指的是人類知覺上的相似
: 因此若兩個相似的人
: 機器如果判斷為相似
: 也只能說 人覺得相似 機器也覺得相似
: 機器如果判斷為不相似
: 也只能說 人覺得相似 但機器覺得不像
: 而不是可以用機器判斷來推論人的知覺
: 機器判斷的邏輯跟人類是差非常多
: 結論
: 1. 根本用錯方法 不能用人臉識別分數推論人臉相似程度
: 2. 就算用對方法 機器覺得像不像不能推論人覺得像不像
我不是機器學習相關領域的,不過我對下面那個confidence score有點興趣,
這東西翻譯好幾種,信心指數,信賴分數,可信度 etc,
但照我的理解,應該是程式對這次判斷結果的自信度,
那意思似乎就會完全顛倒呢...
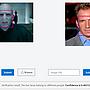
用第一張圖來看,程式判斷這兩人不同人,但信心指數只有0.1xxx...
那代表程式其實非常不確定,幹意思就是這兩張照片超像的阿!像到程式根本無法確定!
有沒有機器學習領域的版友出來打我臉,解釋一下confidence score真正的涵義,
順便幫大家漲點知識吧。
--
如果一個人不會好好組織他的思想,也不會通順的把想法寫下,
又不能給讀者提供更多樂趣,而竟將之寫在紙上,
那他就是在輕率濫用他的閒暇和他的紙張
--羅馬共和末期演說家 西賽羅 (Marcus Tullius Cicero , 西元前106~西元前43)
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 114.47.181.200 (臺灣)
※ 文章網址: https://www.ptt.cc/bbs/C_Chat/M.1594294106.A.38D.html
→
07/09 19:30,
3年前
, 1F
07/09 19:30, 1F
→
07/09 19:32,
3年前
, 2F
07/09 19:32, 2F
推
07/09 19:37,
3年前
, 3F
07/09 19:37, 3F
→
07/09 19:37,
3年前
, 4F
07/09 19:37, 4F
推
07/09 19:41,
3年前
, 5F
07/09 19:41, 5F

→
07/09 19:41,
3年前
, 6F
07/09 19:41, 6F
推
07/09 19:43,
3年前
, 7F
07/09 19:43, 7F
→
07/09 19:44,
3年前
, 8F
07/09 19:44, 8F
推
07/09 19:44,
3年前
, 9F
07/09 19:44, 9F

→
07/09 19:44,
3年前
, 10F
07/09 19:44, 10F
推
07/09 19:45,
3年前
, 11F
07/09 19:45, 11F
→
07/09 19:45,
3年前
, 12F
07/09 19:45, 12F
→
07/09 19:45,
3年前
, 13F
07/09 19:45, 13F
→
07/09 19:46,
3年前
, 14F
07/09 19:46, 14F
推
07/09 19:46,
3年前
, 15F
07/09 19:46, 15F
→
07/09 19:46,
3年前
, 16F
07/09 19:46, 16F
→
07/09 19:46,
3年前
, 17F
07/09 19:46, 17F
→
07/09 19:47,
3年前
, 18F
07/09 19:47, 18F
→
07/09 19:47,
3年前
, 19F
07/09 19:47, 19F
→
07/09 19:47,
3年前
, 20F
07/09 19:47, 20F
→
07/09 19:48,
3年前
, 21F
07/09 19:48, 21F
→
07/09 19:48,
3年前
, 22F
07/09 19:48, 22F
→
07/09 19:48,
3年前
, 23F
07/09 19:48, 23F
→
07/09 19:49,
3年前
, 24F
07/09 19:49, 24F
→
07/09 19:49,
3年前
, 25F
07/09 19:49, 25F
→
07/09 19:50,
3年前
, 26F
07/09 19:50, 26F
推
07/09 19:52,
3年前
, 27F
07/09 19:52, 27F

→
07/09 19:54,
3年前
, 28F
07/09 19:54, 28F
→
07/09 19:55,
3年前
, 29F
07/09 19:55, 29F
→
07/09 19:59,
3年前
, 30F
07/09 19:59, 30F
→
07/09 20:12,
3年前
, 31F
07/09 20:12, 31F
→
07/09 20:12,
3年前
, 32F
07/09 20:12, 32F
推
07/09 20:14,
3年前
, 33F
07/09 20:14, 33F
推
07/09 20:17,
3年前
, 34F
07/09 20:17, 34F
推
07/09 20:18,
3年前
, 35F
07/09 20:18, 35F
→
07/09 20:18,
3年前
, 36F
07/09 20:18, 36F
推
07/09 20:19,
3年前
, 37F
07/09 20:19, 37F
推
07/09 20:21,
3年前
, 38F
07/09 20:21, 38F
→
07/09 20:21,
3年前
, 39F
07/09 20:21, 39F
→
07/09 20:21,
3年前
, 40F
07/09 20:21, 40F
→
07/09 20:21,
3年前
, 41F
07/09 20:21, 41F
推
07/09 20:23,
3年前
, 42F
07/09 20:23, 42F
推
07/09 20:26,
3年前
, 43F
07/09 20:26, 43F
→
07/09 20:26,
3年前
, 44F
07/09 20:26, 44F
→
07/09 20:26,
3年前
, 45F
07/09 20:26, 45F
→
07/09 20:26,
3年前
, 46F
07/09 20:26, 46F
推
07/09 20:39,
3年前
, 47F
07/09 20:39, 47F

→
07/09 20:41,
3年前
, 48F
07/09 20:41, 48F
→
07/09 20:41,
3年前
, 49F
07/09 20:41, 49F
噓
07/09 21:05,
3年前
, 50F
07/09 21:05, 50F
推
07/09 21:06,
3年前
, 51F
07/09 21:06, 51F
→
07/09 21:06,
3年前
, 52F
07/09 21:06, 52F
→
07/09 21:06,
3年前
, 53F
07/09 21:06, 53F
→
07/09 21:07,
3年前
, 54F
07/09 21:07, 54F
→
07/09 21:08,
3年前
, 55F
07/09 21:08, 55F
噓
07/09 21:08,
3年前
, 56F
07/09 21:08, 56F
→
07/09 21:11,
3年前
, 57F
07/09 21:11, 57F
→
07/09 21:12,
3年前
, 58F
07/09 21:12, 58F
→
07/09 21:12,
3年前
, 59F
07/09 21:12, 59F
→
07/09 21:51,
3年前
, 60F
07/09 21:51, 60F
→
07/09 21:52,
3年前
, 61F
07/09 21:52, 61F
推
07/10 03:31,
3年前
, 62F
07/10 03:31, 62F
→
07/10 03:32,
3年前
, 63F
07/10 03:32, 63F
→
07/10 03:32,
3年前
, 64F
07/10 03:32, 64F
→
07/10 03:32,
3年前
, 65F
07/10 03:32, 65F
→
07/10 03:32,
3年前
, 66F
07/10 03:32, 66F
推
07/10 11:54,
3年前
, 67F
07/10 11:54, 67F
→
07/10 11:54,
3年前
, 68F
07/10 11:54, 68F
→
07/10 13:57,
3年前
, 69F
07/10 13:57, 69F
噓
07/10 14:26,
3年前
, 70F
07/10 14:26, 70F
推
07/10 15:36,
3年前
, 71F
07/10 15:36, 71F
→
07/10 15:37,
3年前
, 72F
07/10 15:37, 72F
→
07/10 15:40,
3年前
, 73F
07/10 15:40, 73F
→
07/10 15:40,
3年前
, 74F
07/10 15:40, 74F
討論串 (同標題文章)
完整討論串 (本文為第 1 之 7 篇):