作者查詢 / twinkleAshed
作者 twinkleAshed 在 PTT 全部看板的留言(推文), 共1054則
限定看板:全部
看板排序:
4F→: 不是都用optiscaler去override嗎?223.137.172.129 05/15 16:55
5F→: 這叫做community support.223.137.172.129 05/15 16:55

18F→: https://i.verb.tw/t1dsgap4.gif223.137.128.142 05/13 04:24
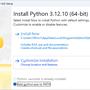
1F→: PYTORCH_MIOPEN_SUGGEST_NHWC114.136.26.210 01/14 01:13
2F→: 我記得上游已經修掉了.114.136.26.210 01/14 01:13
3F→: upscale跟interpolation不會不會有114.136.26.210 01/14 01:14
4F→: regression了.114.136.26.210 01/14 01:14
5F→: *多打一個不會.114.136.26.210 01/14 01:15
8F→: 就我前幾天在Linux上的測試, TheRo114.136.26.210 01/14 01:23
9F→: ck的miopen並沒有包含ck solver,114.136.26.210 01/14 01:23
10F→: 想要3D implicit GEMM solution114.136.26.210 01/14 01:23
11F→: 的話, miopen得要另外build.114.136.26.210 01/14 01:23

1F→: 上游的ComfyUI會直接把MIOpen關掉.223.136.202.134 01/01 06:41
2F→: 用ovum的方法不曉得會不會有衝突.223.136.202.134 01/01 06:42
7F→: ROCm7的主要改進都在CDNA上.114.136.248.84 09/26 13:13
8F→: 所以這版在RDNA上跟之前不會有114.136.248.84 09/26 13:14
9F→: 太大差異.114.136.248.84 09/26 13:14
19F→: *除非你用的是MI300之類的.114.136.248.84 09/26 17:15
20F→: 不然得寄望新架構把AI/ML單元下放114.136.248.84 09/26 17:17
21F→: 到消費級顯卡上.114.136.248.84 09/26 17:17
13F→: 這該不會只是做個介面把自己稍微223.140.40.174 09/22 15:37
14F→: 動動手就能實現的東西包裝起來吧?223.140.40.174 09/22 15:37
20F→: FSR/DLSS本就基於TAA.223.137.94.243 09/16 19:30
21F→: 所以其實使用二者其一還是會過一遍223.137.94.243 09/16 19:31
22F→: TAA.223.137.94.243 09/16 19:31
23F→: 主要還是利用Upscaler的算法來去躁223.137.94.243 09/16 19:32
30F→: 何況有些遊戲會將TAA加入早期渲染223.137.94.243 09/16 19:38
31F→: 中, 硬關反而會引入更多瑕疵.223.137.94.243 09/16 19:38
28F→: RTX PRO 6000 Blackwell:223.136.216.203 09/05 10:21
31F→: 前面幾個月黃牛囤貨不知道屯多少,223.136.216.203 09/05 10:26
32F→: 不曉得統計上是不是有排除掉.223.136.216.203 09/05 10:26
33F→: 如果沒有, 在我看來其實很正常.223.136.216.203 09/05 10:27
71F→: FSR4的相容性問題主要是因為WMMA,114.137.211.155 08/26 16:28
72F→: int8也不會比較快, 因為RDNA3沒有114.137.211.155 08/26 16:28
73F→: sparsity(應該).114.137.211.155 08/26 16:28
89F→: 不賣牙膏, 改賣膠水.42.72.113.191 07/25 16:21
90F→: x86S砍掉難道就不是屈就OS嗎?42.72.113.191 07/25 16:23
94F→: 不是一直以來都能在BIOS底下關嗎?42.72.113.191 07/25 16:26
95F→: 結果實測反而沒比較好.42.72.113.191 07/25 16:26