[試題] 107-1 李琳山 數位語音處理概論 期中考
課程名稱︰數位語音處理概論
課程性質︰電機系/資訊系選修
課程教師︰李琳山
開課學院:電資學院
開課系所︰電機系
考試日期(年月日)︰107.11.28
考試時限(分鐘):120
試題 :
註:部分數學式以LaTeX語法表達。
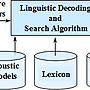
1. Take a look at the block diagram of a speech recognition system in Figure 1.
https://imgur.com/undefined

(a) In the block of front-end processing, why doe we use the filter-bank? (4
%)
(b) Explain the rules of the acoustic models, lexicon, and language model in
Figure 1? (12%)
(c) Why do we need smoothing in the language model? (2%)
(d) Which part includes the HMM-GMM? (2%)
2. Given a HMM \lambda = (A, B, \pi) with N states, an observation sequence
\bar{O} = o_1...o_t...o_T and a state sequence \bar{q} = q_1...q_t...q_T, d-
fine
\alpha_t(i) = Prob[o_1...o_t, q_t = i | \lambda]
\beta_t(i) = Prob[o_{t+1}...oT | q_t = i, \lambda]
(a) What is \sum_{i=1}^N\alpha_t(i)\beta_t(i)? Show your results. (4%)
(b) What is \frac{\alpha_T(i)\beta_t(i)}{\sum_{j=1}^N\alpha_t(j)\beta_t(j)}?
Show your results. (4%)
(c) What is \alpha_t(i_a_{ij}b_j(o_{t+1})\beta_{t+1}(j)? Show your results.
(4%)
(d) Formulate and describe the Viterbi algorithm to find the best state seq-
uence \bar{q}^* = q_1^*...q_T^* giving the highest probability
Prob[\bar{O}, \bar{q}^* | \lambda]. Explain how it works and why backtracki-
ng is necessary. (4%)
3. Explain what is a tree lexicon and whuy it is useful in speech recognition.
(8%)
4. (a) Given a discrete-valued random variable X with probability distribution
{p_i = Prob(X = x_i), i = 1,...,M}. \sum_{i=1}^M = 1.
Explain the meaning of H(X) = -\sum_{i=1}^M p_i[\log(p_i)].
(b) Explain why and how H(X) above can be used to select the criterion to s-
plit a node into two in developing a decision tree. (4%)
5. (a) What is the perplexity of a language source? (4%)
(b) What is the perplexity of a language model with respect to a corpus?
(4%)
(c) How are they related to a "virtual vocabulary"? (4%)
6. Please answer the following questions.
(a) Explain what a triphone is and why it is useful? (4%)
(b) Explain why and how the unseen triphones can be trained using decision
tree. (4%)
7. What is the prosody of speech signals? How is it related to text-to-speech
sunthesis of speech? (6%)
8. Explain why and how bean search and two-pass search are useful in large voc-
abulary continuous speech recognition. (8%)
9. Please briefly describe LBG algorithm and K-means algorithm respectively. W-
hich one of the above two algorithms usually performs better? (Explain your
answer with description, not just formulate only.) (8%)
10. Homework problems (You can choose either HW2-1 or HW2-2 to answer).
HW2-1
(a) We added the sp and sil model in HW@-1. How can they be used in digital
recognition? (2%)
(b) Write down two methods to improve the baseline of the digital recogniz-
er and explain the reason. (4%)
HW2-2
(a) Why do we use Right-COntext-Dependent Initial/Final to label? (2%)
(b) What characteristics can we use to help distinguish the Initials and F-
inals? (4%)
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 114.24.173.199 (臺灣)
※ 文章網址: https://www.ptt.cc/bbs/NTU-Exam/M.1624747517.A.174.html
→
06/27 11:03,
2年前
, 1F
06/27 11:03, 1F
討論串 (同標題文章)
完整討論串 (本文為第 2 之 2 篇):