Re: [閒聊] 每日LeetCode已回收
1519. Number of Nodes in the Sub-Tree With the Same Label
給你一棵樹 每個 node 都帶有編號和一個字元
要你對每個 node 找出他們的子樹中有多少 node 和他有一樣的字元
自己也包含在內
Example 1:
https://assets.leetcode.com/uploads/2020/07/01/q3e1.jpg
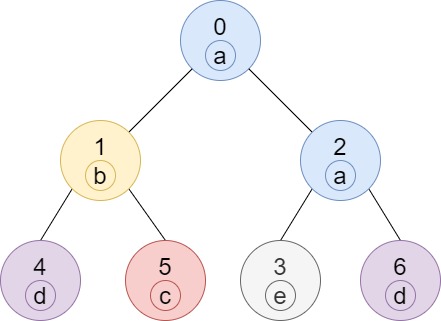
Input: n = 7, edges = [[0,1],[0,2],[1,4],[1,5],[2,3],[2,6]], labels =
"abaedcd"
Output: [2,1,1,1,1,1,1]
以 node 0 為頂點的樹中有兩個 label[0] = 'a' 其他都只有一個
Example 2:
https://assets.leetcode.com/uploads/2020/07/01/q3e2.jpg
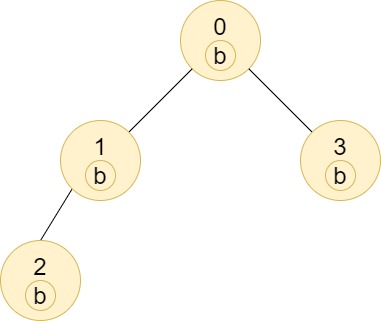
Input: n = 4, edges = [[0,1],[1,2],[0,3]], labels = "bbbb"
Output: [4,2,1,1]
Example 3:
https://assets.leetcode.com/uploads/2020/07/01/q3e3.jpg
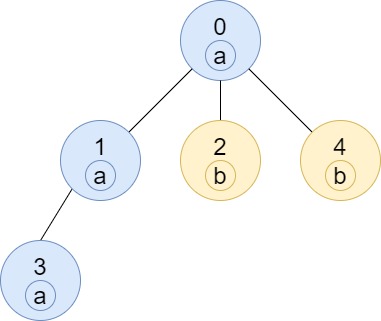
Input: n = 5, edges = [[0,1],[0,2],[1,3],[0,4]], labels = "aabab"
Output: [3,2,1,1,1]
思路:
1.對每個 node 都需要知道以他們為頂點的子樹 各個字元的數量 用 dict(node) 代表
如果對每個 node 都遍歷整棵子樹算出 dict(node) 時間複雜度會是O(n^2)太高
可以在 dfs child 的時候回傳以 child 為頂點的子樹的 dict(child)
這樣就不用每個 node 都重算一次
最後看 dict(node) 中 key = label[node] 的 value 是多少就好
2.為了不在 dfs 的時候往回走可以記一下目前 node 的 parent
當然也可以用 visited 去記
Python code:
class Solution:
def countSubTrees(self, n: int, edges: List[List[int]], labels: str) ->
List[int]:
neighbor = defaultdict(list)
for a, b in edges:
neighbor[a].append(b)
neighbor[b].append(a)
res = [0]*n
def dfs(node, parent):
count = Counter(labels[node])
for nb in neighbor[node]:
if nb != parent:
count += dfs(nb, node)
res[node] = count[labels[node]]
return count
dfs(0, -1)
return res
今天第一次知道 Counter() 可以直接用加的...
--
蛤?
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 111.251.200.200 (臺灣)
※ 文章網址: https://www.ptt.cc/bbs/Marginalman/M.1673520172.A.D2E.html
→
01/12 20:19,
2年前
, 1F
01/12 20:19, 1F
→
01/12 20:54,
2年前
, 2F
01/12 20:54, 2F
→
01/12 21:09,
2年前
, 3F
01/12 21:09, 3F
→
01/12 21:09,
2年前
, 4F
01/12 21:09, 4F
→
01/12 21:10,
2年前
, 5F
01/12 21:10, 5F
討論串 (同標題文章)
完整討論串 (本文為第 189 之 719 篇):