Re: [爆卦] 中央研究院詞庫小組大型語言模型
※ 引述《xdbx (羊阿兵)》之銘言:
: ※ 引述《dean1990 (狄恩院長)》之銘言:
: : 本魯也很好奇問了一些問題,
: : 首先是比較基礎的:
: : https://i.imgur.com/zKhx1A2.jpg

: 現在上不去了 只截到這個
: https://imgur.com/a/evMNmWM
: 你現在問它台灣總統是誰 它會說蔡英文了
: 問它台灣是不是國家 也說會
: 問它簡單的問題都會覺得台灣來的
: 但是電腦不會說謊 轉個彎套它話
: 就會發現資料都是被竄改過了
: 它的根源就是個阿六仔
這個語言模型的最大資料來源都是源自於一個世界開放的語料資料庫
其中中文占的比例很少
中文當中繁體中文的資料更少
因此訓練起來 中文其實都不像樣
同時間訓練台灣的內容資料又更少之又少
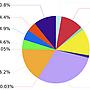
可以看下圖
https://i.imgur.com/zSPlmC5.jpg

繁體中文只有 0.05% 簡體中文有16%
如果真的要避免繁體中文被消滅
應該要正確的選擇我們要在語言AI模型要貢獻那些資料跟模型
不然再幾年對話機器人都內建中國話
台灣就沒有什麼立場了
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 114.137.86.9 (臺灣)
※ 文章網址: https://www.ptt.cc/bbs/Gossiping/M.1696827960.A.B32.html
→
10/09 13:10,
7月前
, 1F
10/09 13:10, 1F
推
10/09 13:12,
7月前
, 2F
10/09 13:12, 2F
→
10/09 13:12,
7月前
, 3F
10/09 13:12, 3F
→
10/09 13:13,
7月前
, 4F
10/09 13:13, 4F
→
10/09 13:13,
7月前
, 5F
10/09 13:13, 5F

推
10/09 13:13,
7月前
, 6F
10/09 13:13, 6F
→
10/09 13:13,
7月前
, 7F
10/09 13:13, 7F
→
10/09 13:13,
7月前
, 8F
10/09 13:13, 8F
推
10/09 13:15,
7月前
, 9F
10/09 13:15, 9F
→
10/09 13:15,
7月前
, 10F
10/09 13:15, 10F
推
10/09 13:16,
7月前
, 11F
10/09 13:16, 11F
→
10/09 13:16,
7月前
, 12F
10/09 13:16, 12F
→
10/09 13:17,
7月前
, 13F
10/09 13:17, 13F
推
10/09 13:23,
7月前
, 14F
10/09 13:23, 14F
→
10/09 13:25,
7月前
, 15F
10/09 13:25, 15F
→
10/09 14:22,
7月前
, 16F
10/09 14:22, 16F
推
10/09 14:38,
7月前
, 17F
10/09 14:38, 17F
討論串 (同標題文章)