Re: HyperThreading
--0023547c8ba5ca62be049c909f65
Content-Type: text/plain; charset=UTF-8
Sysbench OLTP is a very solid test; I'd love to see any results you get from
it, either with Postgres or MySQL as a database server.
http://m-net.arbornet.org/~sv5679/sysbench_nmalloc_df.gif
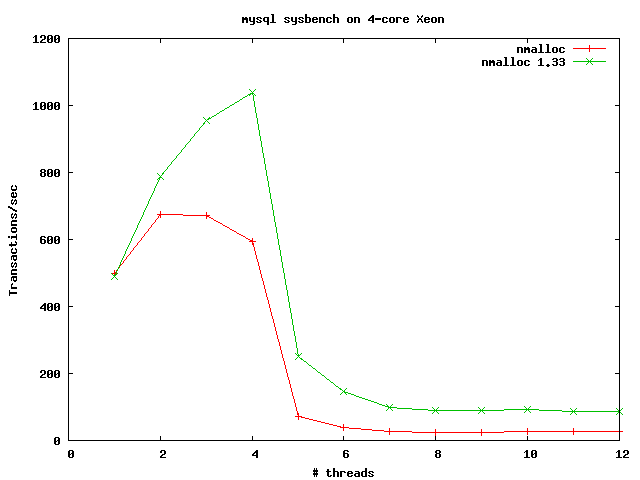
are results from
the spring of last year, very early in the 2.7 branch, for Sysbench/OLTP
with MySQL against Dfly. Despite the title of the graph, this was on an
8-core Xeon (Nehalem-based) system; also not shown on the graph are the UP
kernel results -- the UP kernel with the old libc malloc had a more or less
flat line at 650 transactions/sec (which was distressingly always faster
than the SMP kernel!) and the UP kernel with the new libc malloc had a flat
line at around 800 transactions/sec. With Google's tcmalloc, we had much
better results, but I don't have those numbers handy.
We've really broken up the MP lock since then; the LWKT scheduler has been
changed a lot (round-robin -> fair share); tokens have been reworked twice;
and even the 4BSD scheduler has had work. I'd love to see if we're merely
rearranging deck chairs or if we've actually improved matters...
-- vs
--0023547c8ba5ca62be049c909f65
Content-Type: text/html; charset=UTF-8
Content-Transfer-Encoding: quoted-printable
Sysbench OLTP is a very solid test; I'd love to see any results you get=
from it, either with Postgres or MySQL as a database server.<br><br><a hre=
f=3D"http://m-ne=" rel="nofollow">http://m-net.arbornet.org/~sv5679/sysbench_nmalloc_df.gif">http://m-ne=
t.arbornet.org/~sv5679/sysbench_nmalloc_df.gif</a> are results from the spr=
ing of last year, very early in the 2.7 branch, for Sysbench/OLTP with MySQ=
L against Dfly. Despite the title of the graph, this was on an 8-core Xeon =
(Nehalem-based) system; also not shown on the graph are the UP kernel resul=
ts -- the UP kernel with the old libc malloc had a more or less flat line a=
t 650 transactions/sec (which was distressingly always faster than the SMP =
kernel!) and the UP kernel with the new libc malloc had a flat line at arou=
nd 800 transactions/sec. With Google's tcmalloc, we had much better res=
ults, but I don't have those numbers handy.<br clear=3D"all">
<br>We've really broken up the MP lock since then; the LWKT scheduler h=
as been changed a lot (round-robin -> fair share); tokens have been rewo=
rked twice; and even the 4BSD scheduler has had work. I'd love to see i=
f we're merely rearranging deck chairs or if we've actually improve=
d matters...<br>
<br>-- vs<br>
<br>
--0023547c8ba5ca62be049c909f65--
討論串 (同標題文章)
完整討論串 (本文為第 9 之 16 篇):