作者查詢 / DrTech
作者 DrTech 在 PTT [ Soft_Job ] 看板的留言(推文), 共8447則
限定看板:Soft_Job
看板排序:
全部Tech_Job19780Soft_Job8447WorkinChina4173home-sale3446Gossiping2004Stock1191Salary1157WomenTalk380MenTalk230Beauty161Oversea_Job151MuscleBeach139MobileComm113car96BabyMother81Boy-Girl75L_LifeJob70C_Chat68FITNESS45e-shopping44movie44Fund41sex40AfterPhD35marriage27HatePolitics20ChungLi16Hsinchu16joke16creditcard14PC_Shopping14biker13Miaoli13feminine_sex12Road_Running11StupidClown9Lifeismoney7Bank_Service6Baseball6Finance5ForeignEX5Mechanical5CareerPlan4Contacts4L_TalkandCha4NTU4PhD4PublicIssue4RDSS4motor_detail3Cross_Life2Employee2MayDay2NTTU_CSIE992Trans-nctu2Aviation1BigSanchung1Bio-Job1Chen-Hsing1Chiayi1China-Drama1CHU1Examination1HK-movie1job1Loan1SENIORHIGH1Tainan1teeth_salon1TWSU1<< 收起看板(70)
8F推: 第二個prompt也未必能選擇最佳解,也沒有控制LLM的輸出。11/15 07:16
9F→: 其實第二階任務改成選擇題,選擇候選答案,並結合formatte11/15 07:16
10F→: r控制輸出,其中一種範例:只選擇編號輸出1,2,3,4等選項,11/15 07:16
11F→: 只要消耗one token就能選到答案,成本超低,回應速度超快11/15 07:16
12F→: 。這種速度與成本會幾乎等於one -prompt。11/15 07:16
13F→: 等待與消耗硬體資源成本,根本不用耗費2倍cost。11/15 07:17
14F→: 至於相似度評估,如果你是拿現有別人的embedding模型,要11/15 07:22
15F→: 先用立法院資料驗證模型品質。不然算出來的相似度會非常的11/15 07:22
16F→: 隨機難以參考。11/15 07:22
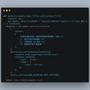
17F→: 範例圖中,八個句子相似度的例子,看起來同語意,但相似度11/15 07:28
18F→: 卻有0.85, 到0.78的落差。顯然,相似度選用的embedding的11/15 07:28
19F→: 模型,未必適合您的專案。11/15 07:28
20F→: 別誤會,架構與技巧本身是沒問題的。只是多提出了實務上更11/15 07:36
21F→: 能省成本,更能驗證效果的客觀做法。11/15 07:36
29F→: 技術沒有高低之分。但所謂的技術,也包含寫履歷的技術,面11/13 08:34
30F→: 試技術。有時候寫履歷的技術或面試技術好,效率高。別人一11/13 08:34
31F→: 個小時的修改,就超越你半年學習了。11/13 08:34
32F→: 同樣是遊戲開發,有些 人會寫成:我業餘開發了一個遊戲。11/13 08:39
33F→: 有些人會寫成,我開發了一個遊戲,讓我學到百人同時上線,11/13 08:39
34F→: 需要注意的資料庫存取技巧,包含…(超跨領域且通用)。這就11/13 08:39
35F→: 是差異。11/13 08:39
36F→: 業餘學什麼技術根本不是重點,你怎麼說這個學習能力的技術11/13 08:41
37F→: ,才是重點。11/13 08:41
2F→: 重點是系統架構設計。rerank完,該怎麼輸出?如果用rerank11/03 16:44
3F→: 完,LLM生成輸出結果,還是永遠有幻覺。如果rerank完,用t11/03 16:44
4F→: op-k個答案事實輸出,就不會有幻覺。11/03 16:44
5F→: 而且當答案只有一個的情況,何必用到複雜的rerank。直接轉11/03 16:50
6F→: 換成搜尋結果 k選一的classification任務,還比較適合。11/03 16:50
12F→: 我只是說最簡單的例子,也可做到不用靠人整理,或不要整理11/03 23:38
13F→: QA。方法就是跟常見的RAG一樣,不整理QA,直接把文章切成c11/03 23:38
14F→: hunk 段落。一樣搜最接近top-K段落,給LLM生成答案,但是11/03 23:38
15F→: 生成答案後,"不要"信任LLM的生成文字直接輸出,使用傳統11/03 23:38
16F→: 的NLP去糾錯(spell correct ion),糾錯的候選只能是chunk11/03 23:38
17F→: 事實中的連續句子。最後輸出糾正到事實的句子。這樣可做到11/03 23:38
18F→: 不整理QA但整個系統只會輸出最正確的事實句子。11/03 23:38
19F→: 方法變形很多啦,但原則就是:LLM只是選擇或決策的工具,11/03 23:44
20F→: 非最後的答案生成輸出。這樣就會有同樣聰明,又永遠是事實11/03 23:44
21F→: 輸出的AI。11/03 23:44
25F→: 我只是舉簡單的例子,你先做要CoT然後最後輸出選項,也可11/04 07:15
26F→: 以啊。其實許多Agent選tool的概念就是這樣,多種tool用選11/04 07:15
27F→: 項讓LLM 選,LLM只限定選1,2,3,4這樣選項,也可控制next t11/04 07:15
28F→: oken只選數字。選tool行為就不會有幻覺,同樣的道理。11/04 07:15
29F→: viper9709總結得很好。不要有幻覺,就是:問答題轉成,事11/04 07:17
30F→: 實的選擇。11/04 07:17
32F→: 同樣的技術,也可以想成AI更通用了,用得更全面了,即可以11/04 08:16
33F→: 用於生成,也可以用於判斷與分類。產品能賺得錢更多了。11/04 08:16
34F→: LLM產品,何必困於於生成或判別二選一。11/04 08:18
35F→: causal language model 從來就沒限制next token該怎麼用,11/04 08:28
36F→: 沒限制下游任務只能用來判別或生成二選一。11/04 08:28
39F→: 你可以去多看論文,OpenAI發表的GPT系列論文,模型評測一11/05 07:34
40F→: 直都不只是用於生成答案任務,甚至評測LLM 排名的知名benc11/05 07:34
41F→: hmark dataset, MMLU系列, 就是選擇題。11/05 07:34
42F→: 這種做法叫本末倒置,質疑了所有做LLM benchmark 研究的所11/05 07:37
43F→: 有團隊阿。11/05 07:38
44F→: 你看到許多LLM leaderboard跑出來的分數,許多題目都是測L11/05 07:41
45F→: LM做多選一的選擇題喔。怎麼大家都這樣利用與評測LLM的能11/05 07:41
46F→: 力,就你認為是本末倒置呢?11/05 07:41
47F→: 再來,什麼叫作"本",以使用者為中心,解決使用者困擾才是11/05 07:46
48F→: 本。一個公司系統需要不會有亂答題的需求。人家才不管你技11/05 07:46
49F→: 術使用是否用得本末倒置,能解決亂生答案的痛點才是本。11/05 07:46
54F→: 純交流技術而言,不需要用到本末導致,高人一等都詞語吧,11/05 10:21
55F→: 不同的技術應用哪有高低之分呢。不用太自卑啦,我只是跟你11/05 10:21
56F→: 交流技術,技術本身並沒有高人一等之說。11/05 10:21
57F→: 能解決使用者問題,何必去分高低呢。11/05 10:22
58F→: 你自己就是做這領域了,你解決hallucination了嗎?可以分11/05 10:28
59F→: 享交流嗎? 至少我在我做的產品都解決了我也很願意跟大家11/05 10:28
60F→: 分享。11/05 10:28

18F→: 真的要禿頭,是沒在分職業或工時的。一堆準時下班的公務員11/03 18:32
19F→: 也骨頭。11/03 18:32
20F→: 禿頭11/03 18:32
73F→: CRUD一分鐘上千次叫開始有難度?單位搞錯吧,一秒鐘才16次11/04 17:31
74F→: 耶。 正常RDBM,CRUD隨便做一秒鐘都上千次transaction才正11/04 17:31
75F→: 常吧。11/04 17:31
8F→: 幻覺為什麼一定要解決才能做AI產生生產力?不用解決也可以11/03 15:41
9F→: 啊。不是所有任務都要靠LLM生成不可靠的資訊。例如很多人11/03 15:41
10F→: 做RAG+QA問答,都無腦用搜候選結果,然後用LLM生成最後答11/03 15:41
11F→: 案,當然一堆幻覺。架構上改成拿LLM當選擇器,或限定next11/03 15:41
12F→: tokens,只能輸出選擇1.2.3.4。在多個答案裡面挑一個,最11/03 15:41
13F→: 後靠程式輸出完全沒關鍵的答案。立刻解決幻覺問題。11/03 15:41
14F→: LLM當特定task模組(不要拿來當最後輸出結果),結合傳統NLP11/03 15:44
15F→: 各種解決方案,任何一個功能任務,都可以"完全沒幻覺",能11/03 15:44
16F→: 力又比傳統NLP強很多。11/03 15:44

17F→: 考察重點是你怎麼解決問題。怎麼解決問題,這個ChatGPT也11/02 02:07
18F→: 會啊。11/02 02:07
159F→: 有用AI寫code的人,才會知道AI多爛啊,打草稿還不是要一行10/29 20:28
160F→: 行看,還有錯10/29 20:28
20F→: 個人目前的實際狀況,即使是GPT-4o,寫出來的程式很少遇到10/28 08:27
21F→: 不用改的,常常連函數都幻想,compile都不會過了。10/28 08:27
22F→: 之前聽了微軟顧問介紹個例子:程式碼語法有錯誤的pull req10/28 08:34
23F→: uest,copilot會自動給出review。我都懶得吐槽,這不用AI10/28 08:34
24F→: 在CI流程,就一定會被擋了,怎麼還需要AI review。10/28 08:34
6F→: 如果履歷只這樣寫,前後端都很難找。因為大學生畢業也這樣10/21 22:03
7F→: 寫。10/21 22:03
16F→: 真佩服能被錄取的人。正常發揮做第一關性向測驗,就會被過10/16 17:23
17F→: 濾掉了。正常照本性填寫,根本進不去面試。10/16 17:23